¶ Combining Descriptions
Very often, datasets will contain multiple descriptions that consist of overlapping and unique data. This tutorial will illustrate how to combine two different descriptions without keeping any of the overlapping data between the two.
¶ The Data
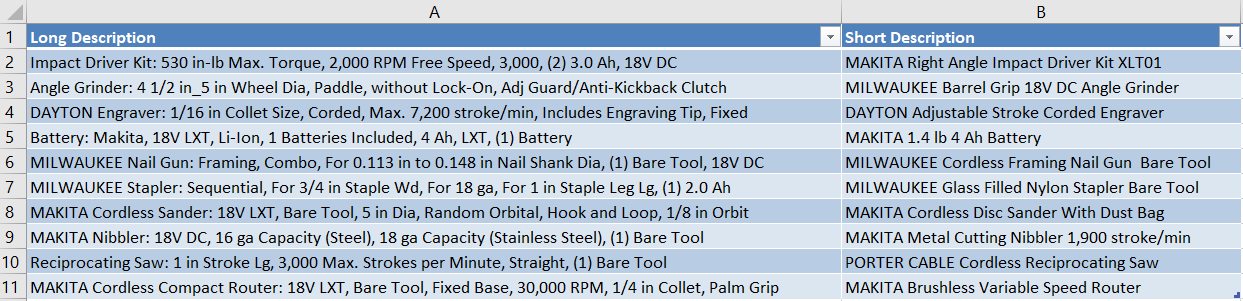
In the dataset above, there are two description columns ("Long Description" and "Short Description") that contain some unique and some overlapping data. Let's get started combining the two while making sure that we do not have any duplicates from the overlapping data.
¶ The Recipe
wrangles:
# Remove any punctuation in preperation to remove duplicates
- standardize:
input:
- Long Description
- Short Description
output:
- Long Description (No Punct)
- Short Description (No Punct)
model_id: xxxxxxxx-xxxx-xxxx
# Convert to lowercase in preperation to remove duplicates
- convert.case:
input:
- Long Description (No Punct)
- Short Description (No Punct)
output:
- Long Description (No Punct, lower)
- Short Description (No Punct, lower)
case: lower
# Tokenize into a list for merge
- split.tokenize:
input:
- Long Description (No Punct, lower)
- Short Description (No Punct, lower)
output:
- Long Description (List)
- Short Description (List)
# Merge description lists
- merge.lists:
input:
- Long Description (List)
- Short Description (List)
output: Description Merged
remove_duplicates: true
# Concatenate list (onto itself) back into a string
- merge.concatenate:
input:
- Description Merged
output: Description WRGLD
char: ' '
# Convert to title case for aesthetics
- convert.case:
input: Description WRGLD
case: title
write:
- dataframe:
columns:
- Long Description
- Short Description
- Description WRGLD
¶ Custom Wrangles Used
A custom standardize wrangle was used to clean up any punctuation to prepare for the removal of duplicates. It is best practice to remove punctuation in this case becuase remove_duplicates (in merge.lists) will not work if a word is followed by a period or comma etc.
Below, you'll find the training data for this custom standardize wrangle:
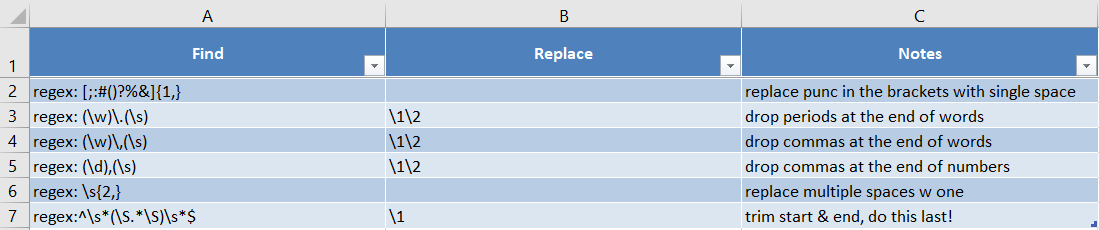
This standardize was carefully built to remove punctuation outside of numbers. That is, any comma within a number (like 3,000) and any decimal point were purposefully left in while removing all others.
¶ Final Output

Now we have a nice, clean description ("Description WRGLD") that has all the data from both of the original descriptions without any duplicated data.
¶ Notes
The data was converted to lowercase for the same reason punctuation was removed. If the case does not match then remove_duplicates will not work.